
90%AI——用StableDiffusion+PS生成二游小姐姐立绘
前言
随着stablediffusion的不断发展,ai绘画的能力也越来越强,定制效果也越来越好。在我(不会画画)自己瞎研究了一段时间后,尝试生成了一些类似动漫游角色立绘的全身图。例子如下(原图可见动态):



可以看到人物的姿势服装之类的没有多少崩坏,背景也勉强能贴合。
当然和真正专业的游戏角色立绘还是没得比,我只是提供一个思路,主要适用于不太会绘画但会一些基础ps操作的朋友(也怕自己过段时间忘了是咋操作的)。
一 生成思路
- 使用sd的整合包web-ui(b站大佬秋叶整合包),同时安装需要的git、Python、cuda等环境
- 下载需要的model、vae、embeddings、lora
- 以我最近生成的图这个红发海盗为例,选择文生图,核心lora模型是这个海盗主题Not Horny Pirate,model和vae随意
- 选择controlnet,导入一个人物姿势

- 选择768*768的分辨率、1.5倍的高清修复(小水管拉高了跑得太慢),迭代步数选35~40步,采样方法选DPM++ 2M SDE Karras,勾选启用Tiled Diffusion(防止最后渲染vae时爆显存),其余参数随意
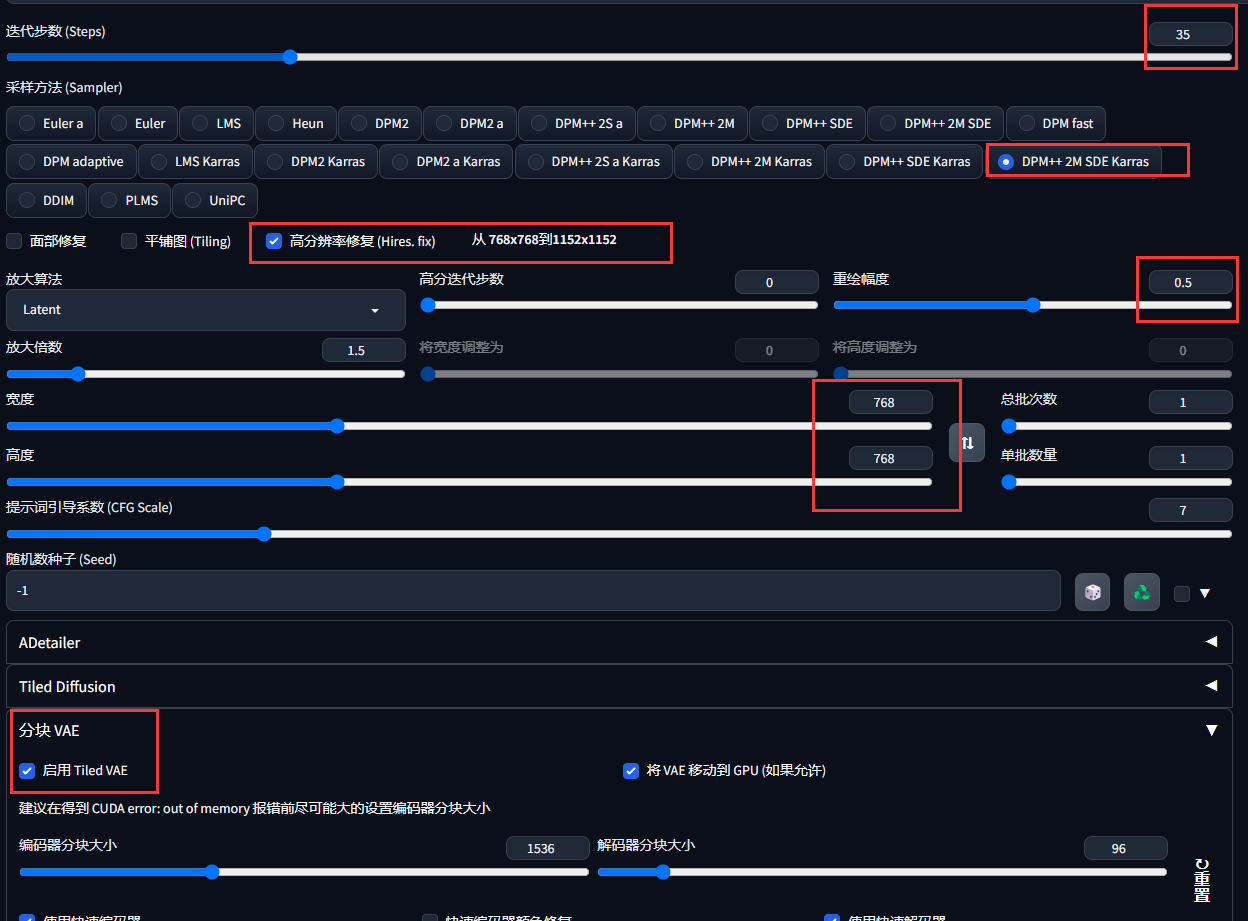
- 跑个5~10张,选择一张画面大致满意的,导入ps作为底图
- 挑选其他图里面满意的元素导入进来,用橡皮擦替换掉底图对应的部分,然后用鼠标(手绘板)把画面明显有bug的地方手动涂改掉(比如画错的手、衣服、背景等),不用涂得太细致,让ai能识别对应的颜色就行
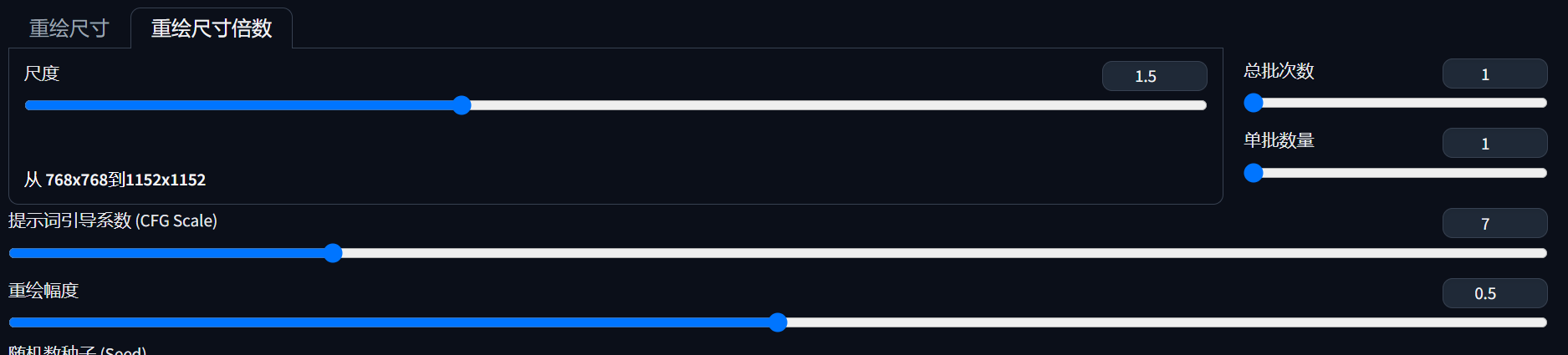
- 把手动改完的图指定分辨率(768*768)导出,进入图生图,其他参数不变,重绘幅度选0.5以下,重绘尺寸还是1.5倍
- 在跑个5~10张,选择一张画面大致满意的,导入ps作为底图,对于不满意想替换的部分再按前面那个流程操作一遍
- 高清化各个地方的细节,其实就是因为我的显卡显存太小没法一次性跑,就可以把想要局部重绘的地方单独裁剪出来,放入图生图里跑,比如:

- 按这个思路把各个想要重绘的地方画完后,在ps里重新拼合,如果还有不满意的地方就再循环一次前面的方法替换
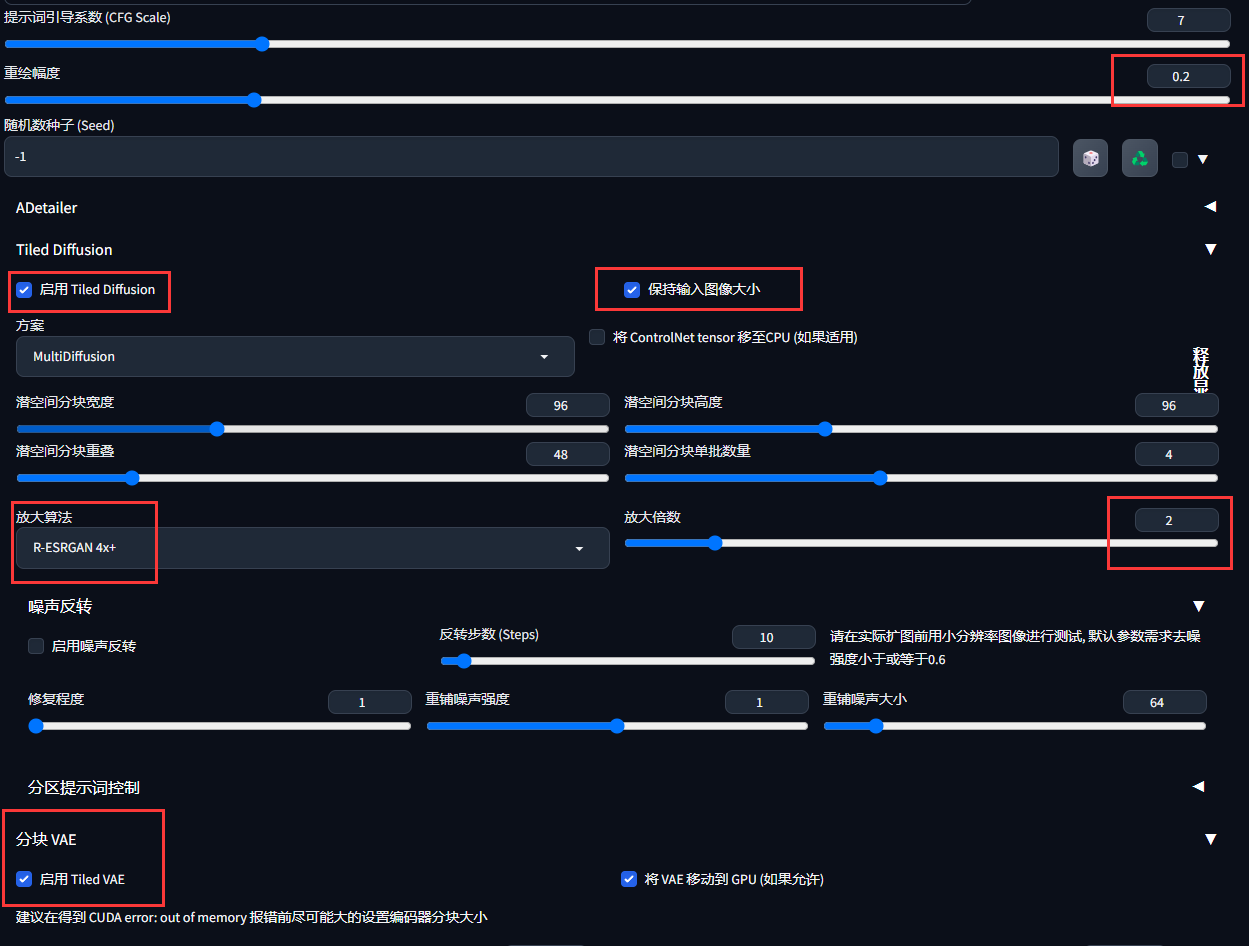
- 导出画面(选择一个设备能跑的极限分辨率),重绘幅度选0.2~0.3,在图生图里勾上启用 Tiled Diffusion,选择2倍放大,放大算法选R-ESRGAN 4x+,其他不变,跑一次(这一次会跑很久,至少几十分钟)
- 成图拥有至少2k以上的分辨率,如果还想继续放大可以导入后期处理里继续放大
- 还可以把完成的图导回ps在调调饱和度、滤镜等等
- 我还做了一个微调的wallpaper-engine版本,我把这种AI图称为90%AI:),一个由90%AI生成+10%人工干预的图 Steam链接

二 名词解释
- 什么是Git:一个代码托管工具,要安装了git才能更新web-ui的新功能 Git 是什么
- 什么是stable diffusion:深入浅出讲解Stable Diffusion原理,新手也能看明白
- 什么是python:stable diffusion的代码通过python语言实现,可以理解为玩游戏前要装的C++、.Net语言库
- 什么是cuda:显卡厂商NVIDIA推出的通用并行计算架构,可以理解为跑ai必要的驱动之一,基本上只有用nv的显卡才能跑ai图(据说a卡和mac也可以没试过、速度应该很慢)
- 什么是web-ui整合包:b站大佬秋叶制作的整合包,用这个整合包就能在浏览器中用图形化的方式操作ai跑图 【AI绘画】Stable Diffusion整合包v4.2发布
- 什么是model、controlNet、lora:这些sd内部的名词太多了,详情可参考b站大佬的免费课程 B站第一套系统的AI绘画课!零基础学会Stable Diffusion
- 什么是ps:全名Photoshop,是由Adobe公司开发的图像处理软件,功能强大也很复杂,如果不是画图我都用光影魔术手:)
三 学习与探索
- 哪儿有stable diffusion中文教程:画小姐姐相关的b站能搜到很多视频,入门推荐 B站第一套系统的AI绘画课!零基础学会Stable Diffusion 建筑/景观/规划类 AI 元技能
- 哪儿有模型、LORA等资源:哩布哩布AI (直达),Civitai(需要魔法,记得屏蔽辣眼的NSFW内容)
- 哪儿有词汇库:Danbooru 标签超市 魔咒百科词典
四 展望未来
AI画图我去年就关注了,当时还是用Google提供的在线生图平台disco diffusion,研究了一大堆参数。但是实际效果并不好,也没有什么定制化的能力,后来sd刚刚出来的时候,也是跑的图都是随机的,实际效果一般,也就没怎么研究了。
直到lora和controlnet的出现,它让ai画图有了定制化的能力,玩家可以定制化的去生成自己想要的图,至此stable diffusion的潜力才得以完全体现,相关的资源也越来越多。(感谢这些热衷研究与分享的大佬们)
我发现自己的构图水平还是太差,当AI能按照你的想法去帮你完成作业时,你的指挥水平就变得尤其重要。对于一张图如何构图、透视、光影等等,要想跑出好图还得有大局观才行:)
今年以来AI生态大爆发,ai画图只是其中的一个缩影,未来的工作生产中必然会越来越多的和AI打交道。话说我看公司都有技术大佬在悄悄研究AI大语言模型的底层代码和算法了。或许我们正在亲历一个时代的变革,未来的浪潮又会将我们带去何方呢?




